
Ausgangslage
Unterwegs leuchtet eine gelbe Warnleuchte auf. Was bedeutet sie? Das Handbuch liegt im Handschuhfach, 300+ Seiten dick. Niemand schlägt es auf. Dabei stehen dort alle relevanten Informationen: Reifendruck, Ölspezifikationen, Warnleuchten, Sicherungskasten, Wartungsintervalle. In der Praxis nutzt sie niemand, weil die Suche in einem solchen PDF umständlich und zeitaufwändig ist.
Vorgehen und Lösung
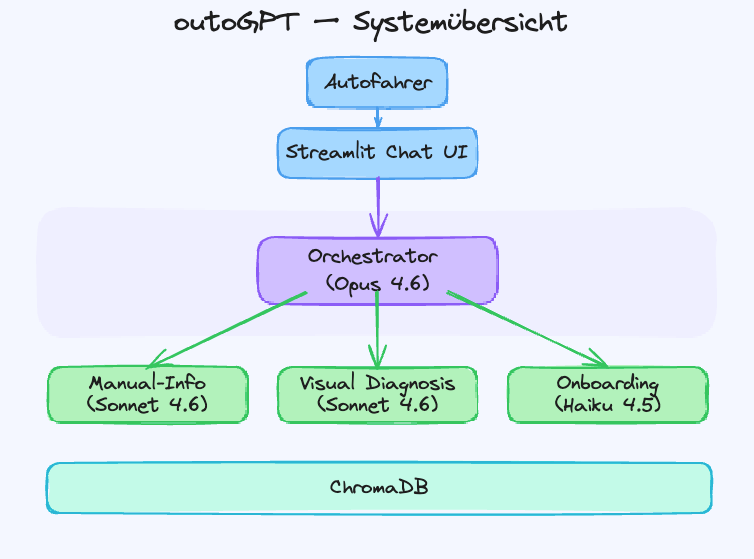
Wir entwickelten ein Multi-Agenten-System, bei dem spezialisierte KI-Agenten zusammenarbeiten. Ein zentraler Orchestrator entscheidet bei jeder Anfrage, welcher Spezialist zuständig ist.
Der Prozess läuft wie folgt ab:
- Frage stellen: Der Nutzer stellt eine Frage in natürlicher Sprache, etwa “Welcher Reifendruck ist empfohlen?” oder “Was bedeutet die gelbe Warnleuchte?”. Der Orchestrator erkennt die Absicht und leitet an den passenden Agenten weiter.
- Handbuch durchsuchen: Der Handbuch-Agent durchsucht über 1.500 indexierte Abschnitte aus dem Fahrzeughandbuch. Abschnitte mit konkreten Werten (Tabellen, Spezifikationen) werden priorisiert, damit die Antwort auf echten Daten basiert, nicht auf Verweisen wie “siehe Aufkleber”.
- Warnleuchte per Foto erkennen: Der Nutzer lädt ein Foto vom Dashboard hoch. Der Bild-Agent identifiziert das Symbol per Bildanalyse, sucht die passende Stelle im Handbuch und liefert eine Diagnose mit Schweregrad (kritisch, Warnung, Info) und konkreten nächsten Schritten.
- Fahrzeugprofil einrichten: Beim ersten Gespräch erfasst ein Onboarding-Agent Marke, Modell und Baujahr. Alle Antworten werden anschliessend auf das spezifische Fahrzeug zugeschnitten.
Jede Antwort enthält Quellenangaben mit Seitennummer und Abschnitt aus dem Handbuch.
Für die Dokumentenverarbeitung setzten wir LlamaParse v2 im Agentic-Modus ein. Anders als klassische PDF-Extraktoren versteht LlamaParse die Struktur eines Dokuments: Es erkennt, dass eine Reifendrucktabelle zur darüberstehenden Überschrift gehört, auch wenn dazwischen ein Seitenumbruch liegt. So bleibt zusammen, was zusammengehört.
Das Besondere: Mit Hilfe eines Vision Language Models (VLM) liest der Parser nicht nur Fliesstext, sondern auch Text auf Bildern, Aufklebern und Diagrammen und wandelt ihn direkt in Markdown um. Zusätzlich erzeugt er kurze Bildbeschreibungen, etwa “Motoröldruck-Warnleuchte” oder “Cockpit mit nummerierten Bedienelementen”. Diese Beschreibungen werden zusammen mit dem umgebenden Text durchsuchbar gemacht. Deshalb findet das System auch Informationen von einem Aufkleber im Kofferraum oder zu einem Warnsymbol im Display, ohne dass Bilder selbst in der Vektordatenbank liegen müssen.
Tech-Stack
- Claude (Anthropic) als Sprachmodell für alle Agenten, gestaffelt nach Aufgabenkomplexität
- LlamaParse v2 für die strukturerhaltende Extraktion aus dem PDF-Handbuch
- ChromaDB als Vektordatenbank
- Streamlit als Chat-Oberfläche mit Bild-Upload und integriertem Dashboard
Demo
Das Ergebnis
Durch diesen Ansatz konnten wir insbesondere folgendes erreichen:
- Sofortige Antworten: Fragen zu Reifendruck, Ölspezifikationen oder Wartungsintervallen werden in Sekunden beantwortet, mit Verweis auf die konkrete Handbuchseite.
- Visuelle Diagnose: Warnleuchten werden per Foto identifiziert und mit einer Handlungsempfehlung versehen, gestützt auf das tatsächliche Fahrzeughandbuch.
- Qualitätsgesichert: Eine automatisierte Eval-Suite mit 40 Testfragen misst die Retrieval-Qualität (75.6% Hit-Rate) und zeigt bei jeder Systemänderung, ob die Antwortqualität steigt oder fällt.
- Sicherheitsrelevant abgesichert: Bei Fragen zu Bremsen, Warnleuchten oder Öldruck empfiehlt das System konsequent die sicherere Option. Prompt-Injection-Schutz und Off-Topic-Erkennung sind integriert.
- Modular erweiterbar: Jeder neue Agent ist eine Klasse und ein Tool-Eintrag. Geplant sind unter anderem ein Werkstatt-Finder und ein Teilevergleich.
- Monitoring integriert: Ein Dashboard zeigt Anfragen, Kosten, Latenz und Token-Verbrauch pro Request.
Fazit
Wer ein Sprachmodell direkt nach Reifendruck oder Ölspezifikationen fragt, bekommt wahrscheinlich plausible, aber falsche Antworten. Das Modell kennt weder das konkrete Fahrzeug noch das richtige Handbuch. Die Kombination aus RAG und spezialisierten Agenten löst genau das: Das System antwortet ausschliesslich auf Basis der tatsächlichen Dokumentation und kann bei jeder Antwort die Quelle mitliefern.
Das Ergebnis ist ein Assistent, der 300+ Seiten Fachwissen in Sekunden zugänglich macht, mit einer Genauigkeit, die eine manuelle Suche nicht erreicht. Dasselbe Prinzip funktioniert überall dort, wo Unternehmen strukturiertes Wissen in PDFs, Handbüchern oder technischen Dokumentationen haben, das heute kaum genutzt wird.
Du möchtest KI-Agenten in deinem Unternehmen einsetzen? Schreib mir auf LinkedIn oder buche einen kostenlosen Call.